Zero Downtime Deploys
When you deploy an application to Patr, it runs in a container. Containers provide an isolated environment for your application to run in, which makes them a popular choice for modern application development. Unlike some other platforms that restart your containers at regular intervals, Patr tries to keep your containers running for as long as possible. This means that your applications can continue running uninterrupted for long periods of time.
Why restarts happen
However, there are certain situations where a container restart is unavoidable. For example, when the underlying infrastructure (like a server or a network switch) undergoes maintenance, experiences a failure or when there is a need to deploy new updates. In these cases, we do everything we can to minimize the impact on your applications, but there may be a short period of downtime when your containers are restarted.
It's important to note that your containers might also restart due to your own actions. For example, when you push a new update to your application, your containers will need to be restarted to apply the changes. So, even though we do everything we can to minimize the number of times your containers are restarted, it's possible that it might happen more frequently than you might expect.
How these restarts affect your users
During these restarts, there might be a brief period of downtime while the new container is starting up and the old one is shutting down. This downtime can range from a few seconds to a few minutes, depending on the complexity of your application and the amount of data it needs to load. This is because of the way containers are designed, which means your application needs to load all of its dependencies again and start listening for incoming requests again. This process usually takes only a few seconds, but it can be longer if your application has a lot of dependencies or if it takes a long time to start up.
To prevent your users from experiencing any downtime during these restarts, you can add a startup probe and a liveness probe to your application. These probes will help ensure that your application is up and running before it starts receiving traffic, and that it remains responsive even after it's been running for a while. By using these probes, you can help ensure that your application stays up and running even during the occasions when your containers need to be restarted.
Adding a Startup Probe and Liveness Probe to your Deployment
To prevent downtime during a container restart, you can add a startup probe and a liveness probe to your application. A startup probe checks if your application has started successfully, while a liveness probe checks if your application is still running properly. If either of these probes fails, Patr will stop serving traffic to the container automatically. By adding these probes, you can make sure that your application is ready to handle traffic before it starts receiving requests, and you can ensure that your users never experience any downtime.
In order to add a probe, navigate to the Manage Deployment screen of your Deployment, and scroll to the Startup Probe and Liveness Probe section.
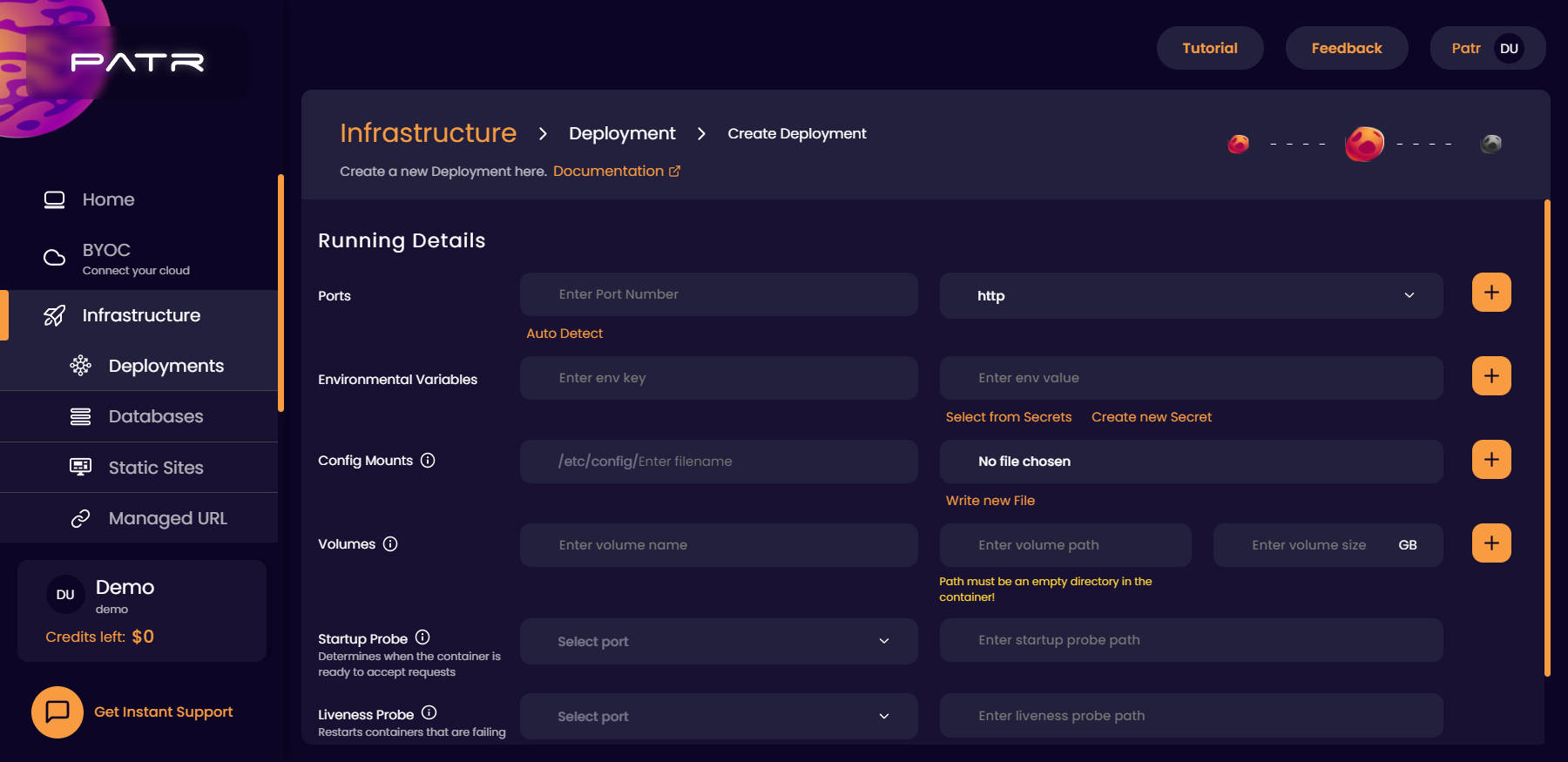
Select a port of the application that you have exposed, and a path that you would like the probe to access. For example, if you choose your port to be 3000 and the path to be /healthz, Patr will make a HTTP request to port 3000, with the path /healthz. If Patr receives a 200 OK response, then the probe is marked as successful. You can read up more on probes in our Advanced Probes Guide.